翻訳チェックを復習しよう(後編)
講演者:産業翻訳者(英日・日英)、WildLight開発者 齊藤貴昭さん
●ヒューマンエラー対策に有効なのは
ヒューマンエラーの対策、検出チェックには、図4の4段階が考えられます。
1番目の「気を付ける」は、良く使われる方法ですが、これは対策ではありません。
個人が行える対策のうち、対策強度が高いのが3番目の「Easy to Notice」です。これは私の考えたやり方ですが、後で説明します。
4番目は、他者によるダブルチェックです。ただし、個人翻訳者が他の翻訳者にチェックしてくれと投げるわけにはいきませんよね。契約で外部に委託してはいけないことも多いので、これはあまり現実的ではないと思います。

この4段階の対策が、各チェック項目に対して、どの程度の対策強度があるかを表わしたのが、図5です。このようにEasy to Noticeは、個人でできる方法の中では、強度が高いということになります。
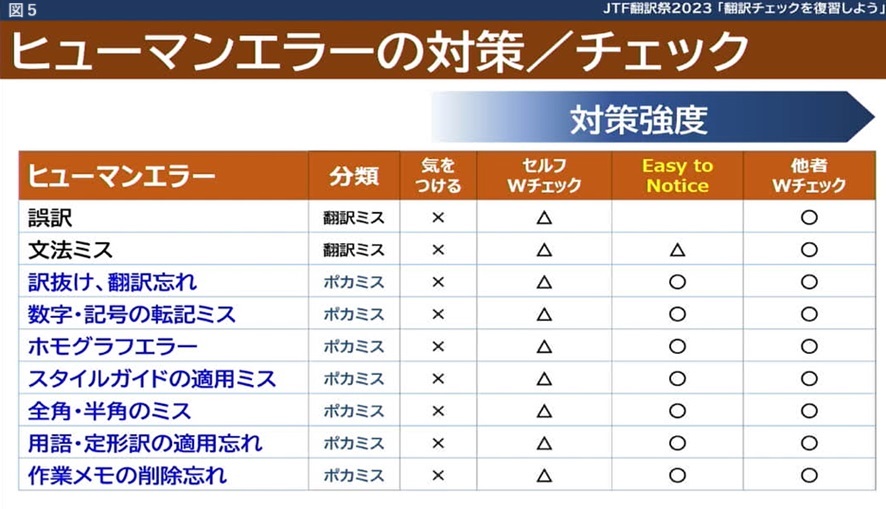
先ほど説明した「感覚→知覚→認知」の3段階のうち、通常のチェックは、認知レベルでチェックしているのがほとんどですが、Easy to Noticeは、知覚に近いレベルまで引き上げて、チェックによる脳の負荷を低減し、検出力を上げることを目的としています。
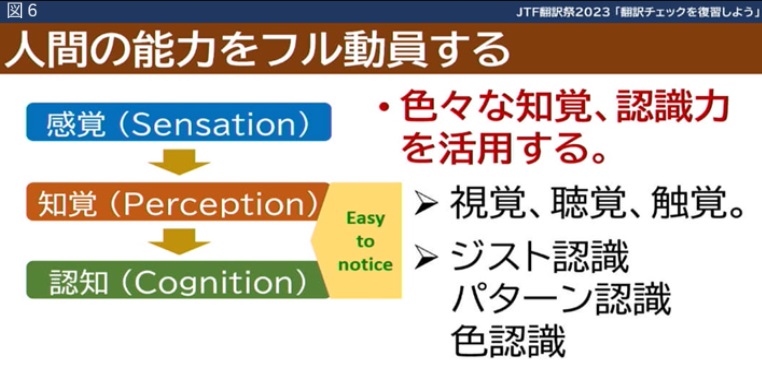
Easy to Noticeとは、例えば「色を付ける」「(モノを)目の前に置く」などによって、意識を集中する箇所を際立たせます。また、数字の色分けなどによって、「知覚」へアプローチして「認知」を軽くするというアプローチになります。図6のようなイメージです。
前出の「ジスト認識」も、この中で使われていくようになります。ちなみに、ジスト認識は悪さをする代表のように言いましたが、逆手にとって使ってやろうというのがこの考え方です。ジスト認識は、「非常に短い時間の枠内、例えば100ミリ秒で複雑な視覚的シーンやパターンの主要な特性や概要を把握する能力」なので、付けた色をチェックするといったことに効いてくるわけです。しかも高速である、認識が容易である、エラーの可視化ができるなどの利点があるようです。
●意識を集中する箇所を絞る
原稿の何千何万という文字をすべて見ていって、その中からエラーを検出することは当然無理なので、スペック(仕様)がはっきりしているのならそれに基づいて、ツールに手助けをさせる。例えば、ツールで色を付けると、遠くから見てもわかるほど容易に検出ができる。これがEasy to Noticeになります。つまり、ヒューマンエラーを検出しやすくするということです。
その時にポイントになることが2つあります。
1つ目は、「意識を集中すべき箇所を絞る」。
ただし、あまりチェックポイントを増やしてしまうと意味がなくなります。色を付けるポイントをどこまで減らせるかは個人差があるので検討すべき点です。
2つ目は、「人間の能力をフル動員する」。
先ほど数詞のチェックの話をしましたが、原文に「2」、訳文に「2」とあったら、文字の形を見て、合っているとすぐわかります。「2」と「4」とあったら、違うなとすぐわかります。でも、「2」の訳文に「two」と書かれたら、形を見ただけでは合っているかどうかはわからないですよね。この「2」は「two」だなと、言葉の意味を理解しないとわからない。これだとミスする可能性が出てきます。
そこで、ツールに「数詞の2には青色を付けること」と指示をすると、2やtwoに同じ青色が付きます。これなら色を見るだけでチェックできるので、単純照合のレベルに入ってきます。桁数が増えても同じです。色を付けることによって、数字の意味を理解しなくてもカラーパターンで認識できるので、単純照合になるのです。
数字の比較はシンボル認識でできるところもあるのですが、色の場合は先ほど出てきたジスト認識が使われるようになるので、より高速かつ正確になる可能性があります。
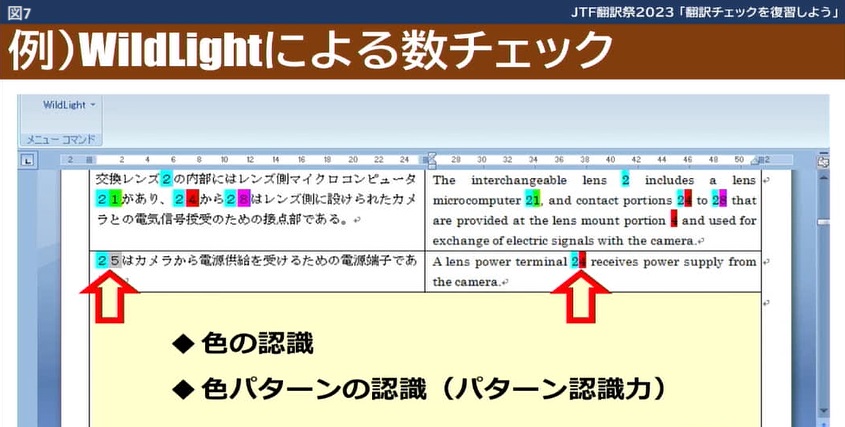
私が作ったWildLightというソフトは、Easy to Noticeを実現するためだけに作ったようなものです。このソフトで、数詞に色を付けた例が図7です。
カラーパターンだけ見て、間違いを見つけられると思います。矢印のところです。色パターンの認識でエラーがチェックできる、遠方から見ても認識できる。頭を使わなくても良否の判断ができるところがポイントになります。
これは数字に色を付けたことによって、参照照合から単純照合にレベルを1段階上げているわけです。こういった改善ができるように、ツールで何か工夫するといいと思います。
用語集も参照照合です。これを単純照合に上げるには、ツールを使って、原文/訳文に用語集の用語ペアで同じ色を付けてやればいいわけです。そうすると、色が同じであれば、用語集の用語が正しく使われていると判断できるようになります。
このように単純照合でチェックできるように、チェックの方法を変えることが大切かと思います。
人間の知覚をフル動員するということでは、聴覚を使ったチェックなども導入されるといいと思います。「どこでも詠太」「テキストトーク」、私が最近つくった「ChotTTS」などの音読ソフトを使うといいです。ちなみに、前に例として挙げたタイポグリセミアの「もろちん」は音読ソフトに読ませると検出できます。私も実験してみましたが、タイポグリセミアはすべて音読ソフトで検出できます。
まとめますと、チェック方法を決めるポイントは、「チェックを分解して、思考の過程が同じものに合わせる」「人間のモードを切り替える」「チェックツールの助けを借りる」ということです。
そしてできるならば、読解チェックよりも参照照合、参照照合よりも単純照合にチェックのやり方をレベルアップさせると、チェックの精度が上がってきます。
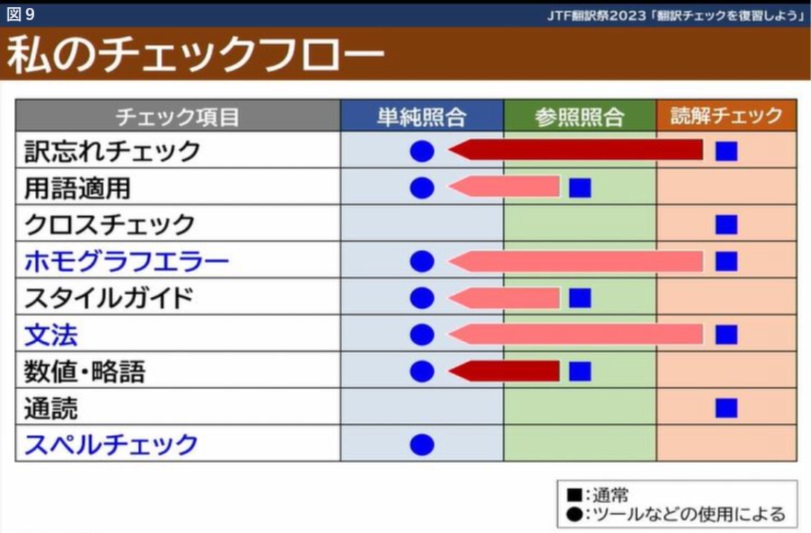
私自身のチェックフローは、ざっくり図8のようになっています。これらのチェックを、先ほどのツールを使うことによって、かなりのものを単純照合に移行させています(図9)。

●ミスをその場で修正できるツールを活用
そもそも、なぜ翻訳チェックをしなければならないのでしょうか。自問自答してみましょう。それは、自分が翻訳でミスをするからです。本来、ヒューマンエラー対策は、ミスしない仕組みを作ることが大切ですから、キー入力している時にミスをしても、その場で修正できるようなツールがあるといいと思います。
翻訳チェックとは離れますが、翻訳時、タイプミスをしたらその場で修正できるツールとして、Microsoft Wordの「オートコレクト機能」やMicrosoft Windows上で動作するAutoHotKeyの「HotString Helper」などがあります。
Wordのオートコレクトは、先ほど「使うな」と言ったじゃないかと言われそうですが、使い方を工夫すればいいのです。図10はひとつの例です。
「が」や「を」などの助詞が重複していたら自動的に修正させる。図10のように登録することによって、オートコレクト機能により、入力ミスした瞬間に自動的に修正されます。なお、後ろに●を付けているのは、オートコレクトが勝手に変更したことを認識できるようにするためです。自分でツールの機能を(十分に理解し、リスク管理を行い)支配して使用するというのがポイントになります。
AutoHotKeyのHotString Helperは、1バイト文字言語に対してのみ有効です。図11のように、Advisorと入力したらAdoviserと自動置換するといったことを定義できます。
ただ、こういう定義をひとつずつ操作して編集するのが大変だという声があると思います。私が作ったアドインソフトのACE(AutoCorrectEditor)では、Wordに登録されているオートコレクトを表にして管理できます。またAutoHotKeyのHotStringHelperの編集も可能になっています。


●翻訳物納品までに行うチェックの流れ
次に大切なのは、翻訳チェックの順番です。図12は私の翻訳チェックフローです。
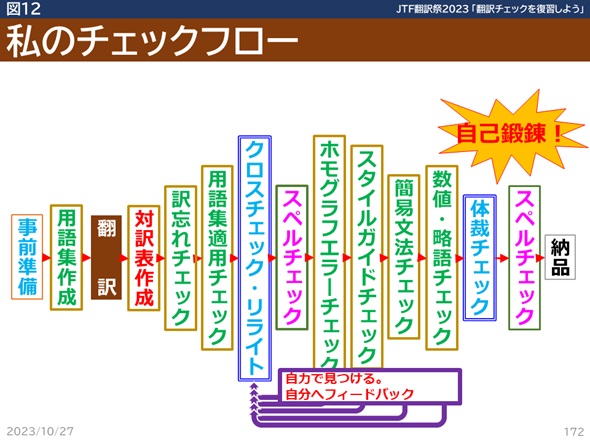
数年前にお話しした時から変わっていません。緑色の項目は、ツールを使ってチェックしています。ピンク色のスペルチェックはWordです。私は必ずWordで対訳表を作ってから、チェックツールでチェックをしていくのですが、「クロスチェック・リライト」が全文を精査するところです。見てわかる通り、スペルチェック以降のチェック項目は、すべてクロスチェックより後にやっています。
なぜツールによるチェックの前に全文チェックをやっているのかというと、私のポリシーとして「翻訳者は職人」と思っているからで、最初からミスをしないためには自己鍛錬が必要だと考えているからです。自分が全文チェックで一度チェックしている項目にもかかわらず、後ろの工程で問題が見つかったら、それを自分にフィードバックし、ミスを出さない方法に改善する。そういう学びと鍛錬のために、こういうフローにしています。
伝えたいのは、翻訳者として間違ったことを気持ち悪いと感じられるようになること。先ほどのフィードバックを何回も繰り返していると、間違った瞬間に間違ったと認識できるようになります。そして気持ちが悪いという感じが脳内に起こるようになりますので、こういう鍛錬をやったほうがいいと思います。基本は、「最初からミスをしない」ということを追い求める。こんなことを考えて、翻訳者として私は仕事をしています。
●チェックフローの決め方
次の6つは、チェックフローの決め方のポイントです。
①一石二鳥を目指す
②自己鍛錬を上手く盛り込む。
③順番を必ず決め、その順番を必ず守る。
④修正で触ったら、再チェックする。
⑤ミスの多いものはフローの前方へ
⑥納品前に必ずスペルチェック
③の「順番」については、品質保証の観点などを考慮し「まずaというチェックをして、次にbというチェックをする」というふうにチェック順序を決めます。決めた順序は必ず守り、実行します。bをやってaをやるという違った順序でチェックをやってはいけません。また、チェックをするたびに順序が変わってはいけません。チェックの順番を定め、その順番を必ず守ることが大切です。
⑤のミスの多いものについては、フローの前のほうへ移動してチェックするようにフローを変えることです。これは、後工程でも問題が検出され、ミスの流出を防止できる可能性が高まるためです。
⑥の納品前に必ずスペルチェックをする。なぜこんな当たり前のことを言っているんだと思うかもしれませんが、スペルミスを含む翻訳物をよく受け取るからです。(つまり、スペルチェックしないで納品する翻訳者が一定数いる)
「チェックフローを決めたらそれを変えない」と言いましたが、納期が短いからといってフローを変更することは絶対やらないようにします。その理由は、定めたフロー、流れ自体も品質保証のひとつのプロセスだからです。フローを変えることによって保証できなくなるものが出てくる可能性があるので、これは必ず守るようにしましょう。
表に分割された文書の影響について述べておきます。時々、チェックしやすいからパラグラフごとに分割して表にしてくださいという方がいるのですが、表に分割するとそのセル内の文章だけに意識が集中するようになりがちです(図13)。例えば文脈や前後関係などが見えなくなりやすいので気をつける必要があります。翻訳支援ツールなども同様の影響があり危険ですので、いったん原文スタイルに印刷してチェックするほうがいいと思います。

●禁止用語は辞書にしてツールでチェック
ホモグラフエラーというのは、スペルチェックに引っかからないスペルミスです(図14)。
先ほど例にあげたshiftのfがないスペルミスもそうです。こういった禁止用語、俗語、間違いやすい用語などを辞書にして、それをチェッカーツールやソフトウェアでチェックにかけるなどするといいと思います。音読ソフトを使った音声再生によるチェックも有効です。
生成AIの活用は、今後の研究エリアになると思いますので、あえて今回の講演に入れました。実務上は守秘義務など制限があるのでチェックに利用できない場合が多いと思いますが、使用の許される場合は、原文と訳文を入力して、プロンプトをうまく記述することでチェックに活用することが可能だということは、実験で確認しています。今後、さらに活用が進んでいくと思います。

通読チェックで工夫していることは、次の4点です。
- Fontは、その文書種類にあったものを使用する
- 文書種類によっては、紙でチェックする
- 最終形態で読む
- 目につく見出しこそ、危ないので注意する
フォントはその文書、資料に合ったものを使用すること。これは以前受講したジャパンタイムズの校正セミナーでも言っていたことです。
フォント心理学、タイプグラフティー心理学でも、フォントが感情や認知に影響を与えるということがいわれています。セリフ体とサンセリフ体、ゴシックと明朝など、その文書にあったスタイルにしてチェックをすることが大切です。
また、文書種類によっては紙でチェックする。また、最終形態で読むこと。ツール上でチェックするのはけっこう危険かもしれません。目につく見出しこそ危ないので注意しましょう。
最後にまとめとして、翻訳チェックの要点を図15にあげておきます。

以上で私の話を終わります。ありがとうございました。
(2023 年 10 月 27 日 第 32 回 JTF 翻訳祭 2023 講演より抄録編集)
◎講演者プロフィール

齊藤貴昭(さいとう・たかあき)Terry Saito
産業翻訳者(英日・日英)、WildLight開発者
精密機器メーカーで20年以上にわたり、設計から製造、市場に至るまでの品質保証業務に従事。そのうち5年間の米国赴任、6年間の社内翻訳・通訳を経験。2007年から約10年間、翻訳コーディネーター・社内翻訳者・翻訳事業運営者として翻訳会社に勤務し、製造業の品質保証手法を応用した独自の翻訳品質保証体系を確立した。また、その考え方をベースに「翻訳者が実施すべき翻訳チェック」の考え方をまとめ、自身の翻訳で実践するとともに、JTF翻訳祭などで講演を行っている。翻訳チェック支援を目的として開発したワードマクロ「WildLight」をフリーウェアとして提供している。
1 2